GrADSoft -- A Program-level approach to using the Grid
Mark Mazina, Rice University; Otto Sievert, Holly Dail of UCSD;
with Graziano Obertelli of UCSD and John Mellor-Crummey of Rice.
February 24, 2001
Earlier source documents:
- August 6, 2000 Compiler/Resource Selector Interaction Scenario by
Dail, Sievert, & Obertelli.
- August 24, 2000 version of this document
by Mazina.
- November 13, 2000 version of this
document by Mazina.
This document proposes an alternative to the library-managed grid invocation
approach of the SC00 demo. Cooperative code development has been ongoing
since late September 2000. The current code base documentation is
here.
We believe there is flexibility in the
program-level approach to encapsulate the library-level approach while
sparing grid-aware library writers from much "glue-it-together" work by
providing standard object interfaces and default object instantiations.
Besides reducing work for the library writers, we hope to address the
following issues:
- Compile/distribute activity should be both automated and "lazy" where
possible - build specific executables when first needed and then store
them in repositories. This creates new issues as to whether a
given user wants to allow the time to create executables in order to
get a larger potential resource space.
- In general, we need to accommodate libraries AND source code,
with probably differing levels of grid awareness. This highlights
one of the big challenges on the Program Preparation side of GrADS:
how do we compose models describing individual parts of a user's
program into a meaningful overall model that respects serialization
constraints in the individual models.
- A good application scheduler (and the resource selector within it) needs
both application and environment
characteristics. Any scheduling mechanism that uses only one of these
could produce poor results. However, scheduling using both sets of
characteristics has a "chicken-and-egg" aspect; for example, you want
an accurate performance model to select resources, yet an accurate
performance model cannot be created until the resources are at least
partially known. We address this issue by embracing successive
refinement: each step in the application preparation process has the
ability to alter or refine the current schedule as more specific or
accurate information is available.
- An object oriented design methodology is the first step towards
a distributed design. It also allows easier addition of new
techniques and features, such as dynamic contract re-negotiation and
more software-controlled program preparation work.
This description of the program-level approach is weak on the
actual contract binding and runtime monitoring phases - now that we
feel we have some understanding of how to get *to* the contract binding
phase, I plead for help from the experts (or future experts) in that area.
All comments / suggestions will be greatly appreciated.
Definitions:
- application -- code implementing one or more algorithms to
solve a user's problem of interest. An application will often
be composed of multiple sub-applications. At the highest level,
the application is typically called a Program.
In a non-Grid environment,
sub-applications are typically sub-routine calls.
- problem -- an application plus a set of input data
and other parameters (i.e. we have the problem size plus any
other run-specific parameters specified or desired by the user)
- resource -- a physical device which can be used to perform work.
This device may possibly be reserved, and may possibly be allocated,
but is most commonly shared. Examples: Cray T90, PentiumIII workstation
running Linux, 10Mbit ethernet.
- virtual machine -- a actual collection of
resources selected specifically for a particular problem, and
the topological relationship(s) among these resources. For example, the
virtual machine of a master/worker problem
(i.e. application + input data) might be the machines
dralion.ucsd.edu, soleil.ucsd.edu,
magie.ucsd.edu, and mystere.ucsd.edu,
where soleil is the master and the others are workers.
The term virtual machine can also refer to any abstract
reference to such a collection of resources.
- work allocation -- The bin-packing part of
problem partitioning onto resources. Also see Mapper, below.
- scheduler -- determines a schedule (a concrete description
of an problem's execution resources, work allocation, and other
run-time configuration parameters). Typically schedulers do not
actuate the problem; instead, they determine the time and place
of execution and configure salient problem run-time parameters.
- resource selector -- the part of the scheduler that
selects grid resources appropriate for a particular problem
based on the problem characteristics.
- Application Abstract Resource and Topology (AART) Model --
provides a structured method for encapsulation of application
characteristics and requirements. More formally,
a description of a class of input-data-independent models defined by the
structure of an application. This consists of a collection of
descriptive and parametric resource characteristics plus a description
of the topology connecting these resources. Three fundamental features
of an AART Model are
- The AART Model characteristics describe application
desired resources and topologies
independent of any given run-time data. For example,
the AART Model
contains the kind of resource topology (e.g., machines are arranged
in a two-dimensional mesh) without mention of the exact size of such
a mesh (which is highly data and resource dependent).
Note that topology type is just a characteristic of the application.
- The AART Model characteristics may change based on the
problem size. So the model may be a continuum of
models or a discrete number of very different models based on that
size. Below some application-specific
problem size, any AART Model
will likely specify using a single compute resource at one location.
- The AART Model attempts to describe resources and topologies
necessary for efficient computation, although this version of
this document does not attempt to define efficient.
The purpose of the AART Model is (1) to kick-start the
resource selection process, and (2) provide part of the information
necessary for the Mapper and the Performance Model.
While one can refer to an AART, it should be recognized in such
a case that the Model suffix is implied.
- Intermediate Representation (IR) Code -- this is the GrADS
version of a binary before the virtual machine is selected. The
compiler has done as much as it can do until the virtual machine
composition is known, at which point final compile and link can happen.
But the user should not have to start from untouched code each time
he/she varies the data in a new run of an application,
although the virtual machine is likely going to vary run-to-run.
The term IR Code has traditionally been used in compiler work
to refer to a short-lived transformation of code as it moves
through the compiler's stages; GrADS IR Code
has persistence.
- Mapper -- an object or function that determines exact data
layout on the virtual machine. Not how much data goes to each
compute resource, but which specific data items. The former issue
of work allocation will be roughly solved during resource selection
as how much data is linked directly to number and type of compute
resources selected. The Mapper may choose to tweak the
initial work allocation for efficiency. For example, the
resource selector could suggest a work allocation that
doesn't map into optimal block sizes when exact data layout is
considered. But, as the verb tweak suggests,
the Mapper can't make radical
changes in work allocation - such changes could make the chosen
virtual machine unsuitable for the problem.
The Mapper addresses the classical data decomposition
and layout problem faced by all parallel compilers.
- Performance Model -- a parametric model that produces absolute
or relative performance for the problem
(i.e. application + input data). It's purpose is (1) to help choose
between different possible virtual machines should the
resource selection process result in multiple candidates, (2) to validate
how appropriate the chosen virtual machine is, and (3) to
provide performance metrics for use in runtime monitoring.
- COP -- Configurable Object Program; refer to The
GrADS Project: Software Support for High-Level Grid Application Development,
February 15, 2000
- PPS & PES -- Program Preparation System and Program Execution System;
refer to The GrADS Project: Software Support
for High-Level Grid Application Development, February 15, 2000
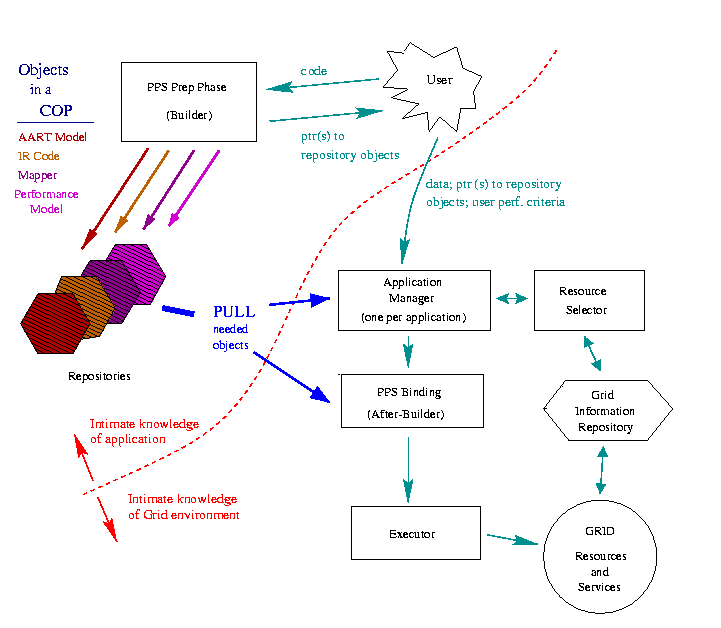
The functionality / services provided by each component:
- PPS Prep Phase (aka the Builder)
- The builder should process the code infrequently, much in the way
we think of current compilers behaving. Some day in the future, the
common case will be the builder just returning pointers to
existing repository objects. Until then, the builder will create most or all
all the following:
- AART Model object.
- IR Code object.
- Mapper object.
- Performance Model object.
All four of the above objects collectively make up the
Configurable Object Program (COP)
- Note that the COP itself is a short-lived object, but the (sub)objects
that make up a COP will have shelf life in one or more repositories.
- Looking beyond the earlier definitions of each of these (sub)objects
in the Configurable Object Program:
- AART (Application Abstract Resource and Topology) Model object
- The program-level AART Model will consist of AART Model objects
describing the various pieces of the application: the user code,
PSE/numeric libraries, performance monitoring libraries. The user code
alone may actually be represented by a series of AART Model objects
based on the phases of the computation.
- The program-level AART Model must be able to compose these multiple
AART Model objects while respecting serialization constraints in the
individual models. (A major open research question is "how?").
- The topology-type characteristic will typically have a
dimensionality (e.g. 3-D mesh) or a number of levels (e.g. trees).
The current AART Model is designed to describe characteristics at both the
total-program level and characteristics that apply to specific
dimensions or levels of the topology. Because of this, the
topology-type characteristic also has a role as a meta-characteristic;
determining what other lists of characteristics may exist. An example:
the application needs a mesh topology, 2-D, roughly square;
balanced communications down the columns critical for performance.
- IR Code object
- The program-level IR Code object will consist of IR Code objects
describing the various pieces of the application: the user code,
PSE/numeric libraries, performance monitoring libraries and any other code
necessary for the application to run.
- For PSE/numeric libraries that have
already been GrADized and the GrADS performance monitoring libraries,
these Intermediate Code objects should already exist either as
self-contained objects or as stubs that pass on to the Binding Phase
information on which library binaries to include in the final executable.
- Any high level optimization efforts during the Binding Phase
will use this intermediate representation.
- Mapper object
- Full instantiation deferred until resource selection is complete;
this object will initially consist of methods to build the
Mapper given the AART Model, Virtual Machine, plus meta-data about the
input data; the size of the problem being perhaps the only essential
piece of meta-data.
- If the Mapper tweaks the work allocation for efficiency,
it can only do so to the extent the Virtual Machine doesn't have to
change; otherwise a feedback loop to the Resource Selector will be
necessary. An example of a safe tweak would be to shift work
around as long as the available memory on each proposed compute resource
is not exceeded.
- Performance Model object
- Full instantiation deferred until the Mapper is complete;
this object will initially consist of methods to build the
Performance Model given the AART Model, Virtual Machine, and Mapper.
- The Performance Model encapsulates both the AART Model and the
Virtual Machine. The contract development and monitoring system(s) will
interface with the Performance Model, not directly with the
AART Model and the Virtual Machine.
- The Performance Model will be the PPS component that accepts
feedback from the contract monitoring system
- Application Manager
- Serves as the user interface; acquires from the user the input
data and other run-specific parameters specified by the user.
- Coordinates activities of components by storing and passing
around pointers to objects and by invoking object methods.
(see scenario below for the sequence of operations the
Application Manager must do.)
- May be specializable for each application. This allows
the data and control flow to be adapted to the application of interest.
Hence each running application has an Application Manager. The issue
of whether multiple Application Managers cooperate is an open research
issue.
- Resource Selector
- Collects info on current Grid environment from Grid Information
Repository
- Uses the AART Model expanded with information on input-data
and parameters for selection criteria,
- Returns one or more proposed virtual machines and a suggested
load-balanced work-allocation based solely on amount of work.
(The Mapper is responsible for actual data layout.)
- Returns or provides query methods for resource
load, communication link performance, confidence values, and
expected stability of these values over time for the proposed
virtual machine.
- PPS Binding Phase (aka After-Builder, dynamic optimizer)
- Invokes Mapper to develop code for actual data layout,
i.e. the exact block cyclic distribution for LU.
- Chooses appropriate communication mechanism(s) i.e. can we use
multicast effectively?
- Optimizes code for chosen distribution, architecture(s),
communication mechanism, etc and completes final build.
- Grid Information Repository
- Holds information about the Grid environment.
- Holds pointers to the pieces of the COP.
- Executor (Big Opaque Box to me at this time)
- Does contract binding.
- Loads and starts code on virtual machine. I assume the code loads the
application data.
- Monitors performance, measuring against the Performance Model,
records data on actual behavior.
- At end of application, releases resources and stores
"completed" Performance Model in a repository for off-line PPS analysis.
How does this compare to the July 2000 diagram developed at
the ANL workshop?.
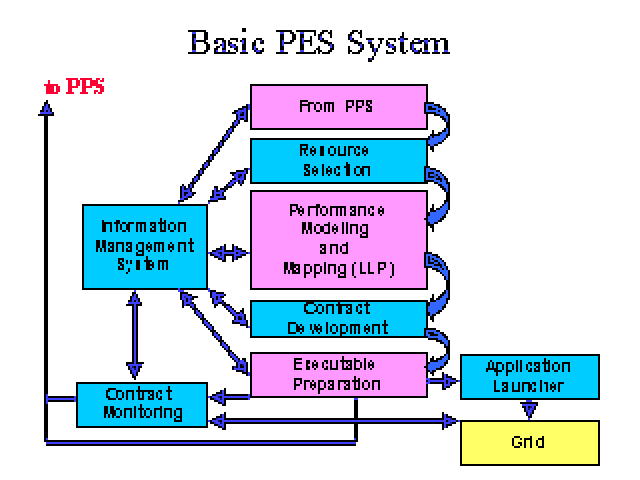
This paper addresses an overlapping view of the GrADS universe as compared
to the above diagram that came out of the July workshop at ANL (aka Fran's
diagram). First, the July diagram is more a high-level partitioning of
the universe into logical blocks of responsibilities; while we focus more
on object interactions just above the actual API level.
We don't have the expertise to address in any significant way
- Contract Development
- Contract Monitoring
- Application Launching
The upper left intimate knowledge of application area on our
diagram fills out the "mist" of what the PPS is doing in the ANL diagram.
We also consolidated the Performance Modeling and Mapping and
the Executable Preparation functionality into a single PPS binding
phase. This doesn't address how Contract Development interacts
with the binding phase as already noted.
Our design adds an Application Manager which can be thought of
as sitting between all the other components, coordinating information
flow. While we show objects in the COP as being pulled directly out of
repositories by the Application Manager and the binding phase,
in practice, we expect the Information Management System will provide
pointers or handles for retrieval of repository objects.
A very brief scenario.
Our User provides the Builder with source code (may be annotated with
resource selection or performance behavior information) *or* a handle
to an existing IR Code object previously created for the user.
The Builder constructs any required objects and returns a handle to the COP.
Recall the COP includes the IR Code object,
AART Model object, Mapper object, and the Performance Model object.
The User starts the Application Manager. This may be the
standard GrADS Application Manager or a user designed one.
The Application Manager
needs to be passed the handle to the COP, I/O location information,
the problem size information (specifically, information to allow
calculation of memory requirements), plus any desired performance metrics
and other run-specific parameters desired or required.
The Application Manager uses the handle to the COP to retrieve
the AART Model via a pointer, uses it (the AART Model) plus
information about the actual data size to query the Resource Selector.
The Resource Selector takes the incoming model, plus information
about the state of the Grid resources, and develops a proposed
virtual machine. For simplicity, we assume just one in this example.
The Application Manager invokes methods in the Mapper object to
fully instantiate said Mapper. It uses the AART Model and Virtual Machine
as input in this process.
The Application Manager invokes methods in the Performance Model
object to fully instantiate said Performance Model.
It uses the Mapper, AART Model, and Virtual Machine as input in this process.
At this point, the Application Manager can "run" the Performance Model
and determine if the user's problem can be solved with the Grid resources
available.
The Application Manager then calls the PPS Binding Phase, passing it
the COP handle and the user's run-time information.
The PPS Binding Phase invokes the Mapper object for
actual data layout, and creates optimized binaries.
For some Grid-aware libraries, it may
need to arrange for dynamic linking to pre-built libraries for
specific platforms.
The Application Manager then tell the Binding Phase to
pass pointers to the Performance Model object and the binaries to the
Executor. I assume the binaries know where the input data is and
where the output is to go; the Executor should not need to be concerned
with that piece. Recall that at this point, baring dynamic re-configuration
due to poor performance, our topology is known. Even with dynamic
re-configuration, it seems more appropriate to make it the executable's
task to get input - perhaps by first getting a handle from the
Grid Information Repository as to where the data is now.
Then BOB finishes everything (recall Big Opaque Box described
above). Fail-restart should NOT discard the Performance Model object, off-line
analysis will be desired.
Back to GrADS